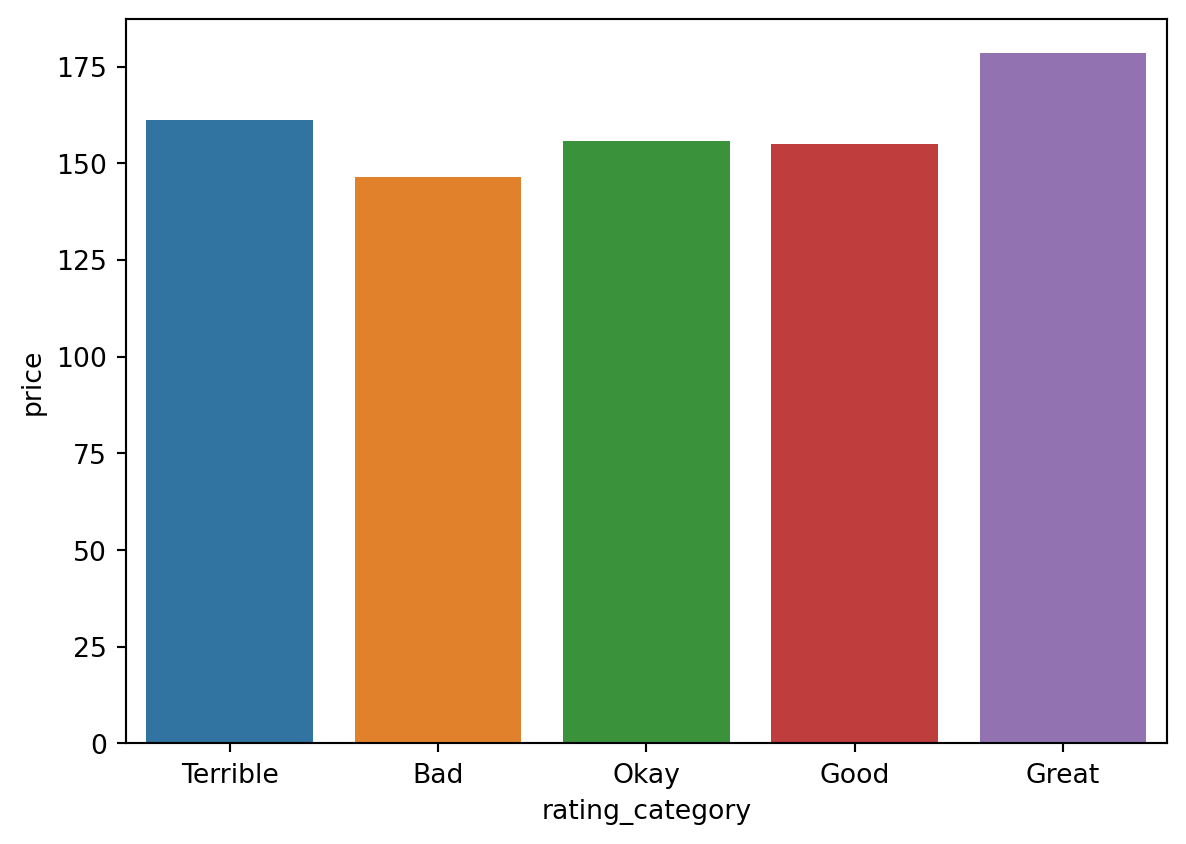Maan Al Neami, Nourah Almutairi, Ammar Alfaifi, Salman Al-Harbi, Dina Alkhammash
Introduction:
In this report we will be analyzing Rome Airbnb properties dataset from inside airbnb and try to analyze it to find what variables influences the income generted by the property.
Why Rome?
We choose Rome because it’s one of the most visited cities by tourists in Europe. Thanks to the rich history, amazing food, and the relatively cheaper prices compared to other major european cities. All of these factors make Rome one of the most sought after investments in the hospitality and tourism industry.
About the dataset source
We got our dataset from inside airbnb. Inside Airbnb is a project that provides data and advocacy about Airbnb’s impact on residential communities. They provide data and information to empower communities to understand, decide and control the role of renting residential homes to tourists.
Data dictionary
Variable
Description
host_name
Name of the host.
neighbourhood
Name of the neighbourhood.
latitude
Used to make an interactive map.
longitude
Used to make an interactive map.
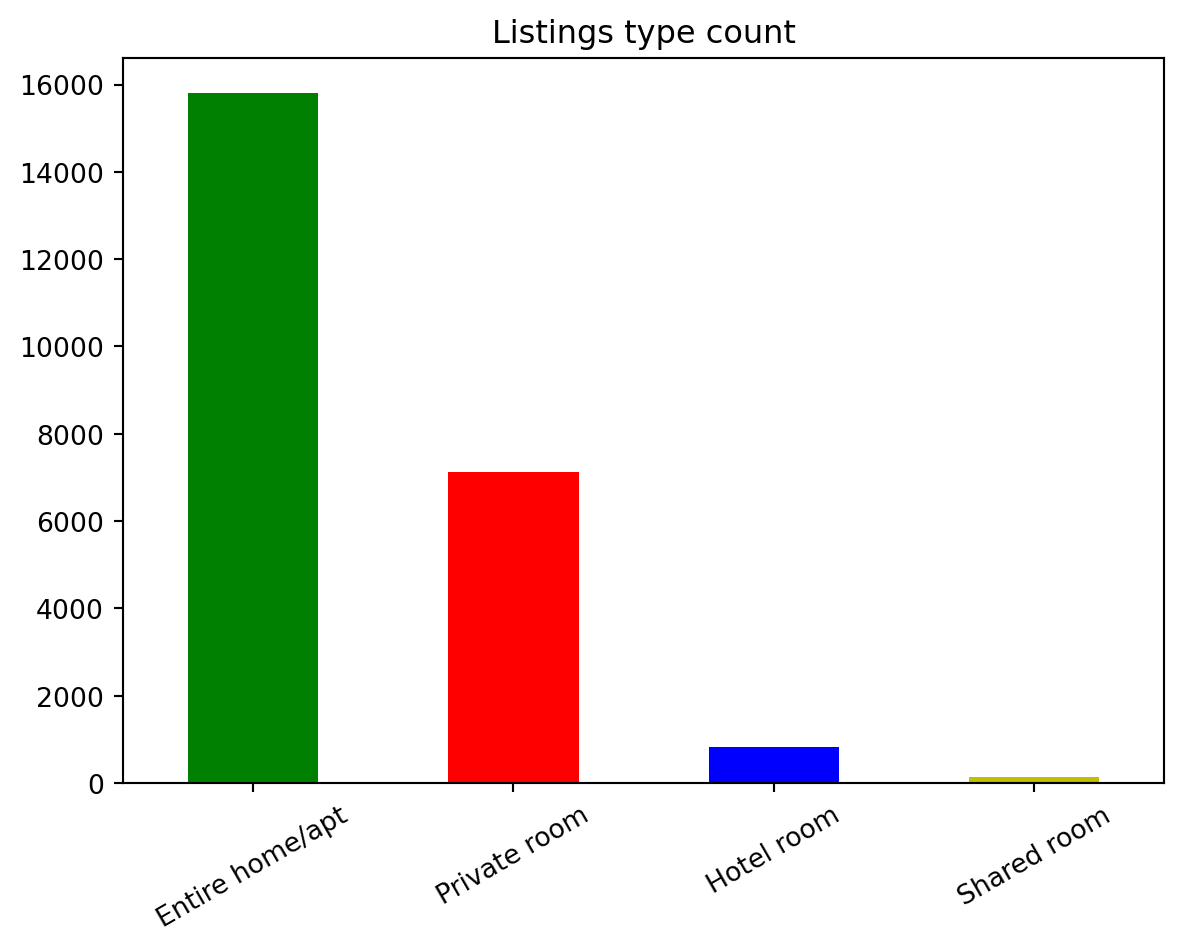
room_type
Entire apt, private room, hotel room.
Price
Price in Euro.
minimum_nights
minimum number of night stay for the listing.
number_of_reviews
The number of reviews the listing has.
last_review
The date of the last/newest review.
availability_365
The availability of the listing x days in the future.
number_of_reviews_ltm
The number of reviews the listing has (in the last 12 months).
amenities
A list of amenities in the listing.
Data Munging
First we will be doing basic data cleaning
Importing libraries and Data
Code
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport plotly.express as pximport plotly.graph_objects as goimport foliumfrom folium.plugins import MarkerClusterfrom folium import pluginsfrom folium.plugins import FastMarkerClusterfrom folium.plugins import HeatMapfrom ast import literal_evalfrom plotly.subplots import make_subplotsdf = pd.read_csv('data/listings.csv')df2 = pd.read_csv('data/listings-detailed.csv')df.head(5)
there was no duplicates but we have null values in host_id, host_name, neighbourhood_group, licence and . We decided to drop the missing values for all columns except reviews.
Second we used apply to convert the price in the dataset to float. We also decided to drop price values of 0 and bigger than 50000 as there was nothing interesting to investigate there and they will miss up our result.
Code
df2["price"]=df2["price"].apply(lambda x : float(x[1:].replace(",","")))df2.drop(df2[df2["price"]>=50000].index,axis=0,inplace=True)df2.drop(df2[df2["price"]==0].index,axis=0,inplace=True)
The amenities column has amenities written as a list inside a string, so we will use literal_eval from ast to turn it into lists of strings, then use explode from pandas to give each element of the list it’s own row, and lastly we will perform a one hot encoding using crosstab
Make this Notebook Trusted to load map: File -> Trust Notebook
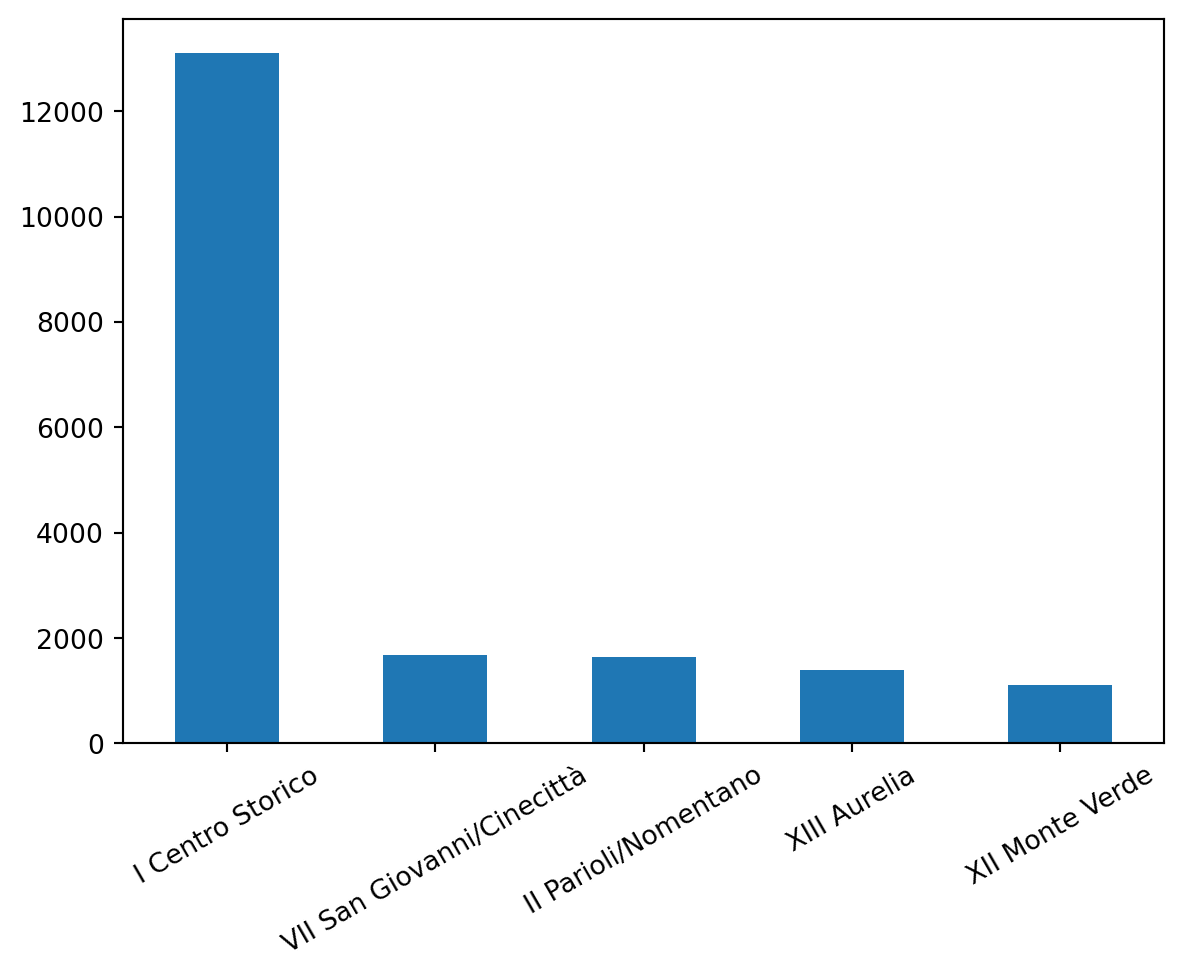
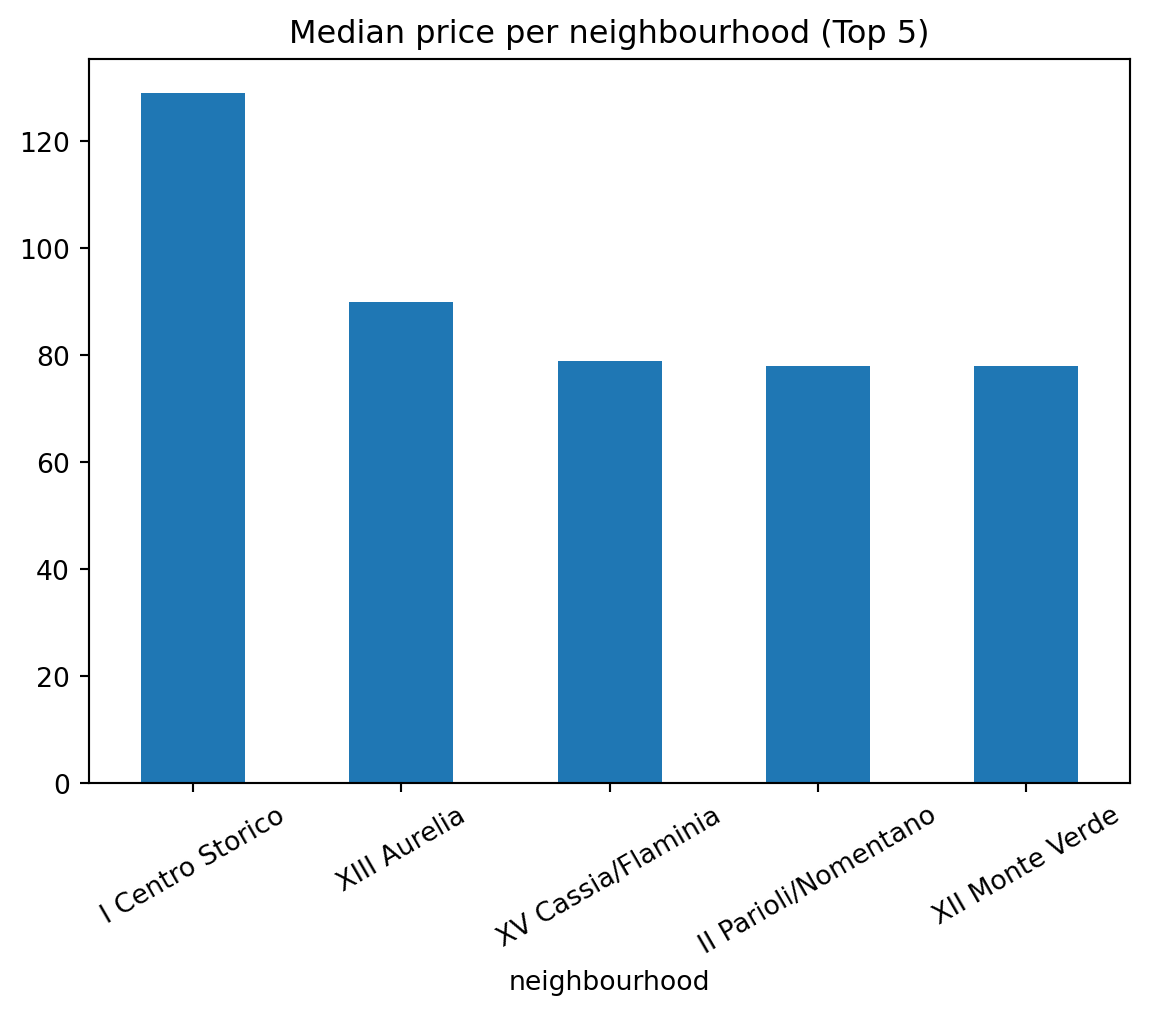
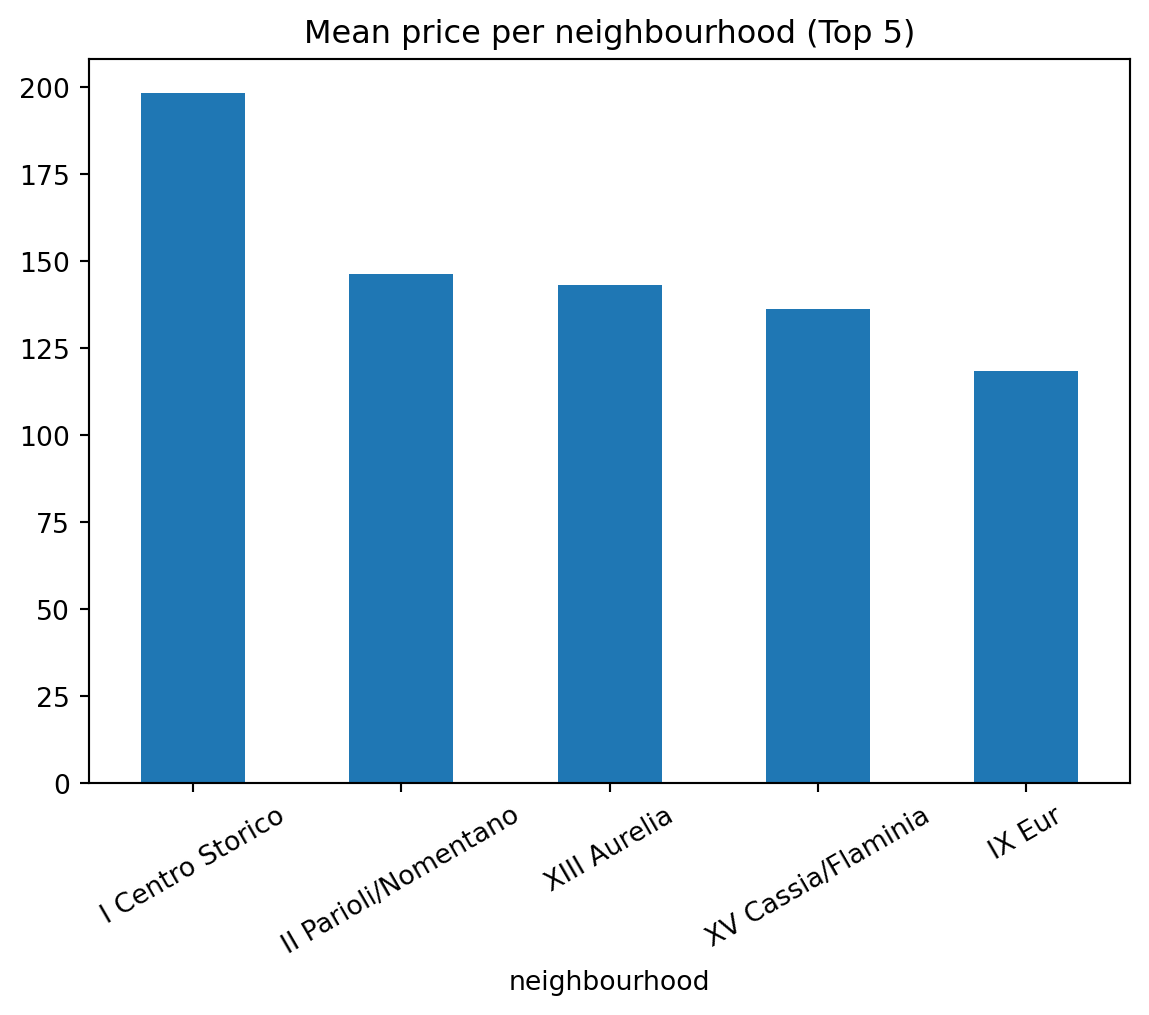
We also see here that the highest prices are in I Centro Storico.
Amenities and Price
What are the most frequent amenities in Roma listings?
Code
amenities = {}for c in df.columns:if"amenities"in c: amenities[c] = df[c].value_counts()[1]amenities_list =sorted(amenities, key=amenities.get, reverse=True)[:10]amenities = {c:df[c].value_counts()[1] for c in amenities_list}fig = px.bar(x = amenities.keys(), y = amenities.values(), title ="Most Frequent Amenities", labels={"y": "Count","x": "Amenities"})fig.show()
We can see that Wifi is the most frequent amenity in Roma’s listings, followed bt Essentials, Hair dryer, and Long term stay. This amenities might be the basic or standard amenities that a vistor to Roma would want.
What is the average price for the most frequent Amenities?
Code
amenities = {}for c in df.columns:if"amenities"in c: amenities[c] = df[c].value_counts()[1]amenities_list =sorted(amenities, key=amenities.get, reverse=True)[:10]amenities = {c:df.groupby(c)['price'].mean()[1] for c in amenities_list}fig = px.bar(x = amenities.keys(), y = amenities.values(), title ="Average Price for the Most Frequent Amenities", labels={"y": "Average Price","x": "Amenities"})fig.show()
from the above graph we can see that listsings that have Air Conditioning, have the highest average price with 185.24
What are the most expensive Amenities?
Code
amenities = {}for c in df.columns:if"amenities"in c: amenities[c] = df.groupby(c)['price'].mean()[1]amenities_list =sorted(amenities, key=amenities.get, reverse=True)[:10]amenities = {c:df.groupby(c)['price'].mean()[1] for c in amenities_list}amenities_count = {c:df[c].value_counts()[1] for c in amenities_list}fig = px.bar(x = amenities.keys(), y = amenities.values(), title ="Average Price for the Most Expnsive Amenities", labels={"y": "Average Price","x": "Amenities"})fig.show()
The most expensive listings amenity is Outdoor seating with a 10.5K, followed by Piastre electric stove, Balcony, and Security cameras.
What is the distribution of the most expensive Amenities?
Code
amenities = {}for c in df.columns:if"amenities"in c: amenities[c] = df.groupby(c)['price'].mean()[1]amenities_list =sorted(amenities, key=amenities.get, reverse=True)[:10]amenities_count = {c:df[c].value_counts()[1] for c in amenities_list}fig = px.bar(x = amenities_count.keys(), y = amenities_count.values(), title ="The Distribution of the Most Expnsive Amenities", labels={"y": "Count","x": "Amenities"})fig.show()
We can see that only one listing has an outdoor seating and Piastre electric stove, while three listings have Balcony and two lsitings have security camera, although these amenities are in expensive listings they seems not to be frequent in Roma.
Distribution of Review’s Rating Scores
Code
for c in df.columns:if"scores"in c: df[c].fillna(df[c].mean(), inplace=True)
add min_booked_nights_past_12m and min_income_past_12m column to the dataset
Code
#the minimum estmtation of the number of booked nights of each listing in the last 12 month (current date = 2022-06-07)romeListings["min_booked_nights_past_12m"]=romeListings.apply(lambda x : x["number_of_reviews_ltm"]*x["minimum_nights_avg_ntm"],axis=1)#the minimum estmtation of the income of each listing in the last 12 month (current date = 2022-06-07)romeListings["min_income_past_12m"]=romeListings.apply(lambda x : x["min_booked_nights_past_12m"]*x["price"],axis=1)
add expected_booked_nights_coming_3m and expected_income_coming_3m column to the dataset
Code
#the expected number of booked nights of each listing in the next 3 month (current date = 2022-06-07)romeListings["expected_booked_nights_coming_3m"]=romeListings.apply(lambda x : 90-x["availability_90"],axis=1)#the expected income of each listing in the next 3 month (current date = 2022-06-07)romeListings["expected_income_coming_3m"]=romeListings.apply(lambda x : (90-x["availability_90"])*x["price"],axis=1)
what neighbourhoods have highest averege price ?
Code
temp=romeListings.groupby("neighbourhood_cleansed")["price"].mean().sort_values(ascending=False).head(5).reset_index()fig = px.bar(temp,x ="neighbourhood_cleansed", y ="price", title ="The highest price per night average of listings within a neighbourhood",color="neighbourhood_cleansed", labels={"y": "Price","x": "Neighbourhood"})fig.show()
what neighbourhoods have highest averege of booked nights over the next 3 month ?
Code
temp=romeListings.groupby("neighbourhood_cleansed")["expected_booked_nights_coming_3m"].mean().sort_values(ascending=False).head(50).reset_index()fig = px.bar(temp,x ="neighbourhood_cleansed", y ="expected_booked_nights_coming_3m", title ="The highest booked nights average of listings within a neighbourhood",color="neighbourhood_cleansed", labels={"y": "Booked nights (next 3 months)","x": "Neighbourhood"},range_y=[0,90])fig.show()
what room types have highest averege price ?
Code
temp=romeListings.groupby("room_type")["price"].mean().sort_values(ascending=False).head(5).reset_index()fig = px.bar(temp,x ="room_type", y ="price", title ="The highest price per night average of listings of a room type ",color="room_type", labels={"y": "Price","x": "Room Type"})fig.show()
what room types have highest averege of booked nights over the next 3 month ?
Code
temp=romeListings.groupby("room_type")["expected_booked_nights_coming_3m"].mean().sort_values(ascending=False).reset_index()fig = px.bar(temp,x ='room_type', y ="expected_booked_nights_coming_3m", title ="The highest booked nights average of listings of a room type",color="room_type", labels={"y": "Booked nights (next 3 months)","x": "Room Type"},range_y=[0,90])fig.show()
what (room type ,neighbourhood) combinations have the highest averege booked nights ?
Code
nBookedNightinNigh=romeListings.groupby(["room_type","neighbourhood_cleansed"])["expected_booked_nights_coming_3m"].agg(["mean","count"])temp=nBookedNightinNigh[nBookedNightinNigh["count"]>11]["mean"].sort_values(ascending=False).head(5)fig = px.bar(x =list(map(str,list(temp.keys()))), y = temp.values, title ="The highest booked nights average of listings for every (Room Type,Neighbourhood) combination", labels={"y": "Booked nights (next 3 months)","x": "(Room Type,Neighbourhood)"},range_y=[0,90])fig.show()
what neighbourhoods have highest minumam income average for the past 12 months ?
Code
temp=romeListings.groupby("neighbourhood_cleansed")["min_income_past_12m"].mean().sort_values(ascending=False).head(5).reset_index()fig = px.bar(temp,x ="neighbourhood_cleansed", y ="min_income_past_12m", title ="The highest minimum income of listings within a Neighbourhood",color="neighbourhood_cleansed", labels={"y": "average minimum income of listings (past 12 months)","x": "Neighbourhood"})fig.show()
what neighbourhoods with the highest expected income average for the next 3 months ?
Code
temp= romeListings.groupby("neighbourhood_cleansed")["expected_income_coming_3m"].mean().sort_values(ascending=False).head(5).reset_index()fig = px.bar(temp,x ="neighbourhood_cleansed", y ="expected_income_coming_3m", title ="The highest expected income of listings within a Neighbourhood",color="neighbourhood_cleansed", labels={"y": "average expected income of listings (next 3 months)","x": "Neighbourhood"})fig.show()
what room types have highest minumam income average for the past 12 months ?
Code
temp=romeListings.groupby("room_type")["min_income_past_12m"].mean().sort_values(ascending=False).head(5).reset_index()fig = px.bar(temp,x ="room_type", y ="min_income_past_12m", title ="The highest minimum income of listings based on room type",color="room_type", labels={"y": "average minimum income of listings (past 12 months)","x": "Room Type"})fig.show()
what room types have highest expected income average for the next 3 months ?
Code
temp=romeListings.groupby("room_type")["expected_income_coming_3m"].mean().sort_values(ascending=False).head(5).reset_index()fig = px.bar(temp,x ="room_type", y ="expected_income_coming_3m", title ="The highest expected income of listings based on room type",color="room_type", labels={"y": "average expected income of listings (next 3 months)","x": "Room Type"})fig.show()
what (room type ,neighbourhood) combinations have the highest averege income ?
Code
nBookedNightinNigh=romeListings.groupby(["room_type","neighbourhood_cleansed"])["expected_income_coming_3m"].agg(["mean","count"])temp=nBookedNightinNigh[nBookedNightinNigh["count"]>11]["mean"].sort_values(ascending=False).head(5)fig = px.bar(x =list(map(str,list(temp.keys()))), y = temp.values, title ="The highest income average of listings for every (Room Type,Neighbourhood) combination", labels={"y": "average income (next 3 months)","x": "(Room Type,Neighbourhood)"},)fig.show()
does the host’s account appearance effects the listing income ?
Code
temp=romeListings.groupby("host_has_profile_pic")["expected_income_coming_3m"].mean().reset_index()fig = px.bar(temp,x = ["No","Yes"], y ="expected_income_coming_3m", title ="",color=["No","Yes"], labels={"y": "average income (next 3 months)","x": "host has a profile pic ?"})fig.show()
Code
temp= romeListings.groupby("host_identity_verified")["expected_income_coming_3m"].mean().reset_index()fig = px.bar(temp,x = ["No","Yes"], y ="expected_income_coming_3m", title ="",color=["No","Yes"], labels={"y": "average income (next 3 months)","x": "is the host identity verified ?"},)fig.show()
Code
temp= romeListings.groupby("instant_bookable")["expected_income_coming_3m"].mean()fig = px.bar(temp,x = ["No","Yes"], y ="expected_income_coming_3m", title ="",color=["No","Yes"], labels={"y": "average income (next 3 months)","x": "can be booked instantly ?"},)fig.show()
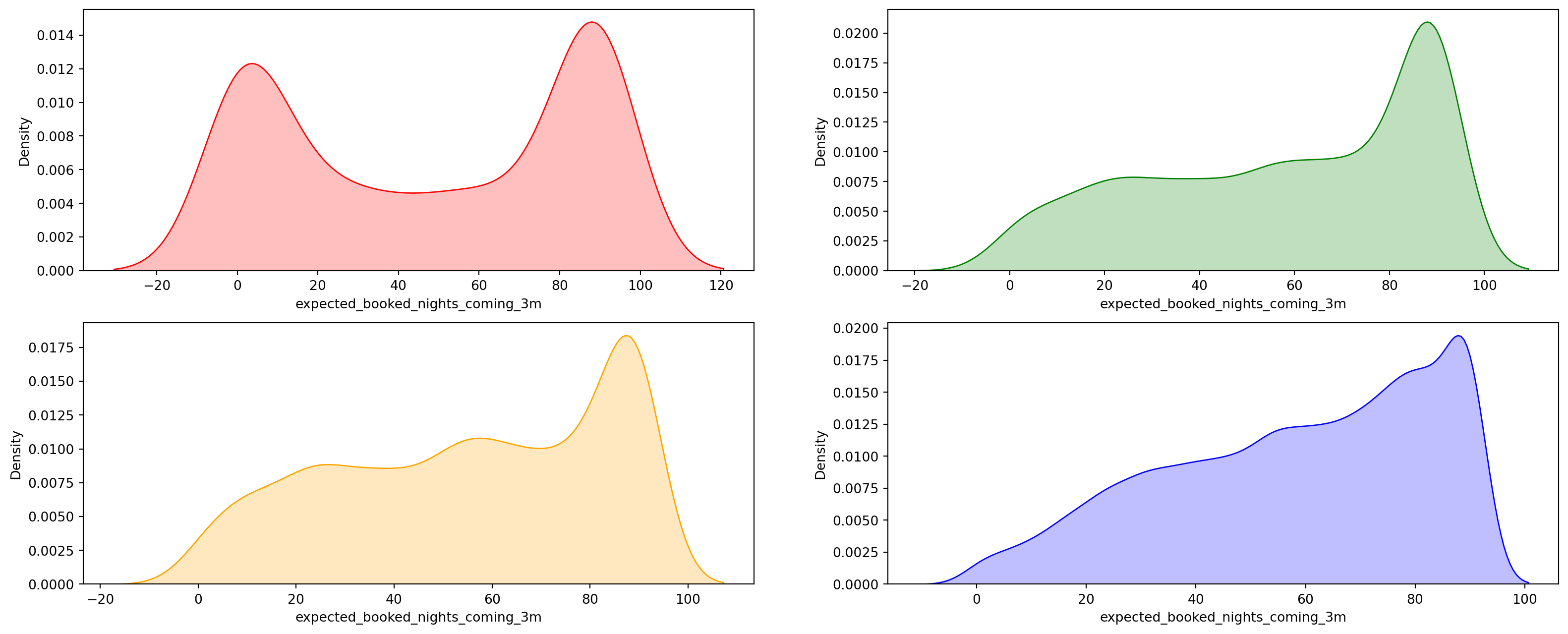
does the response time effects the the densisty of the number of the booked nights ?
Code
f, axes = plt.subplots(2, 2, figsize=(20,8))ax = sns.kdeplot(romeListings[romeListings["host_response_time"]=="a few days or more"]["expected_booked_nights_coming_3m"],x="expected_booked_nights_coming_3m",color="red", fill=True,ax=axes[0,0])ax = sns.kdeplot(romeListings[romeListings["host_response_time"]=="within a day"]["expected_booked_nights_coming_3m"],x="expected_booked_nights_coming_3m",color="green", fill=True,ax=axes[0,1])ax = sns.kdeplot(romeListings[romeListings["host_response_time"]=="within a few hours"]["expected_booked_nights_coming_3m"],x="expected_booked_nights_coming_3m",color="orange", fill=True,ax=axes[1,0])ax = sns.kdeplot(romeListings[romeListings["host_response_time"]=="within an hour"]["expected_booked_nights_coming_3m"],x="expected_booked_nights_coming_3m",color="blue", fill=True,ax=axes[1,1])
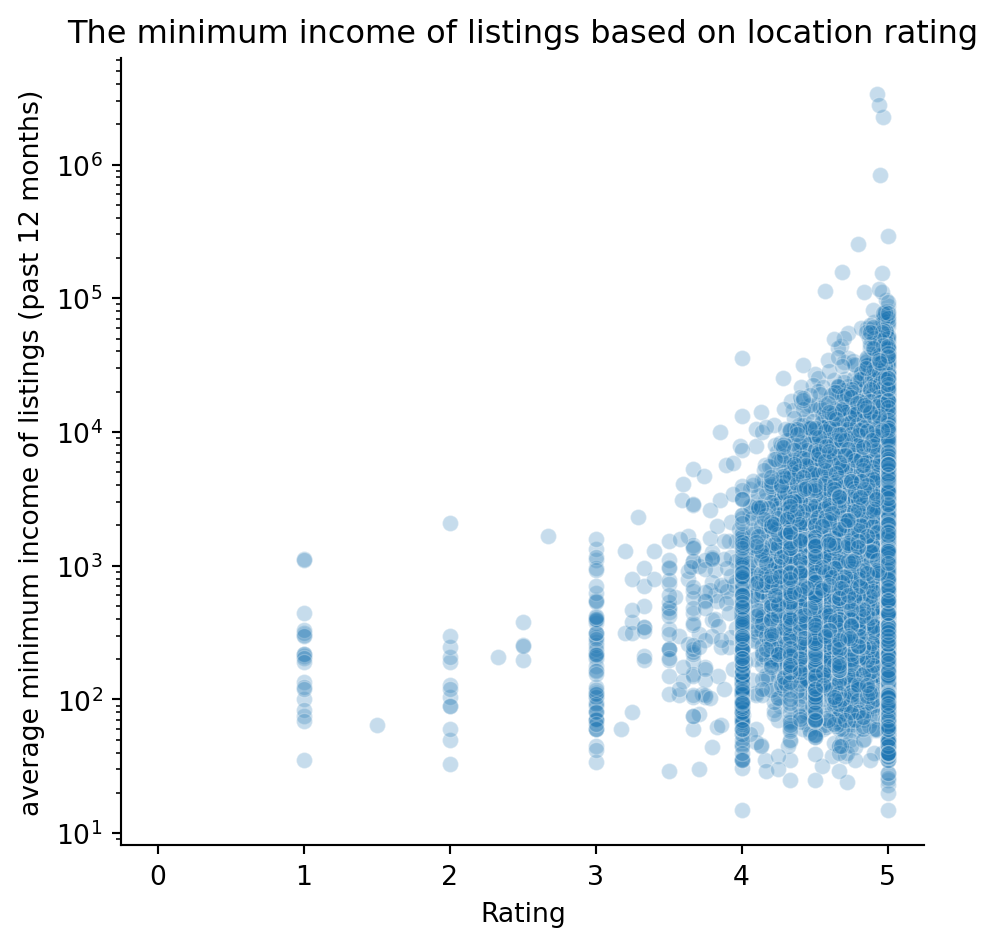
Does the Location Rating effect the minimum income of listings (past 12 months)
Code
romeListings[["rating_location_category", "rating_category", "value_category"]] = df[["rating_location_category", "rating_category", "value_category"]]ax = sns.relplot(data= romeListings, x="review_scores_location", y ="min_income_past_12m" ,alpha=0.25)plt.xticks([0, 1, 2, 3, 4, 5], ["0", "1", "2", "3", "4", "5"])plt.yscale("log")plt.title("The minimum income of listings based on location rating")plt.xlabel("Rating")plt.ylabel("average minimum income of listings (past 12 months)")plt.show()
We can see that there is an upward trend that indicate, that listings with higher location review score had higher average minimum income for the past year.
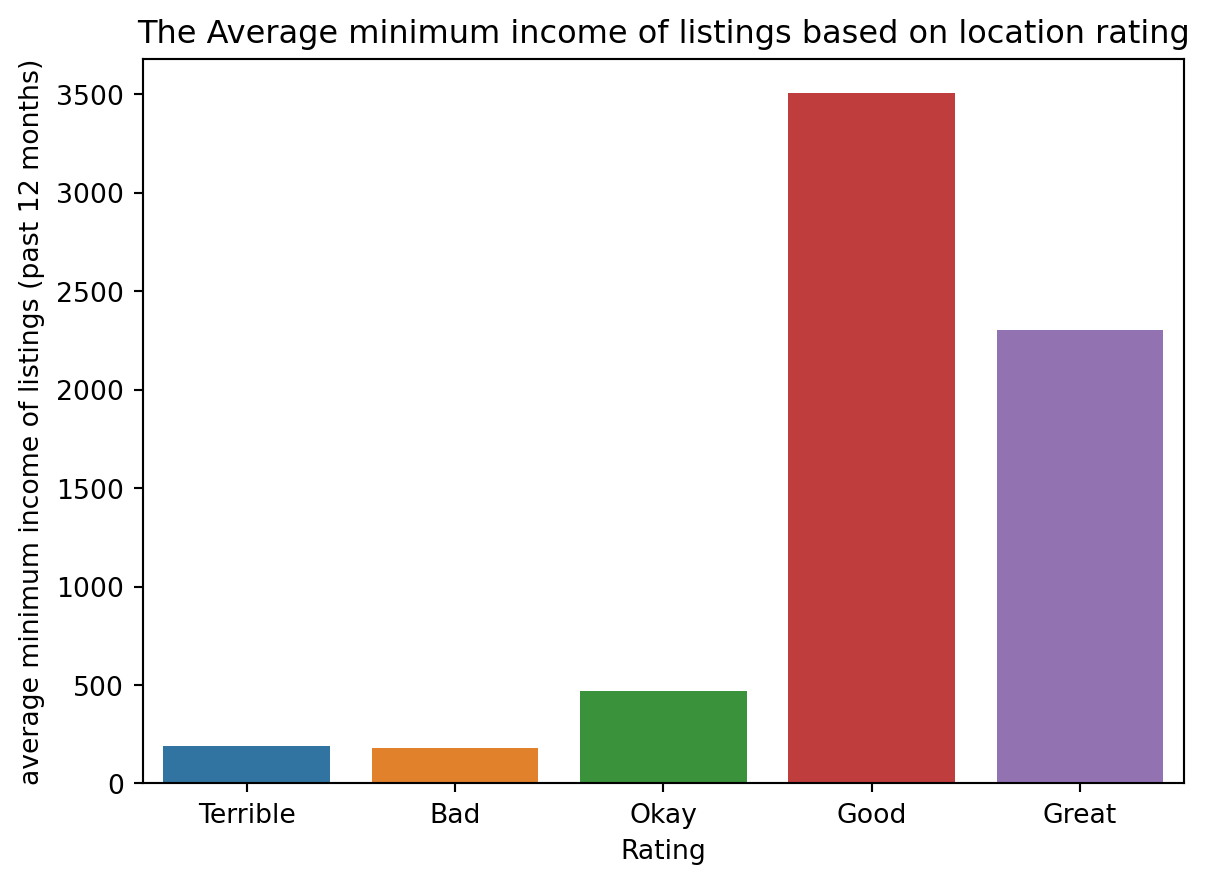
Code
data = romeListings.groupby("rating_location_category")["min_income_past_12m"].mean().sort_values(ascending=False)sns.barplot(x=data.index, y=data)plt.title("The Average minimum income of listings based on location rating")plt.xlabel("Rating")plt.ylabel("average minimum income of listings (past 12 months)")plt.show()
We can see here also that Good and Great, both have higher average minimum income than the rest of the categories.
What about the expected income for the next 3 months? let’s check it out.
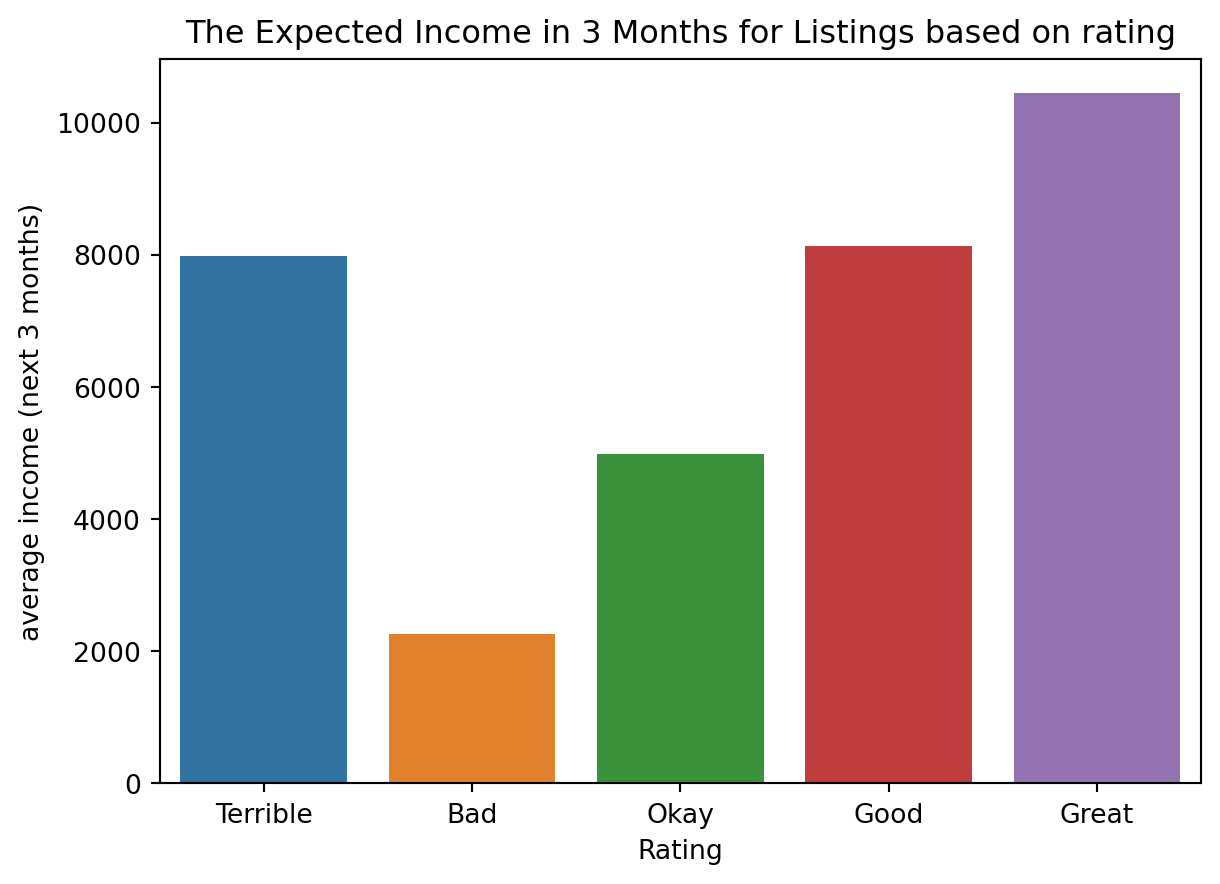
Does the Location Rating effect the expected average income (next 3 months)
Code
data = romeListings.groupby("rating_location_category")["expected_income_coming_3m"].mean().sort_values(ascending=False)sns.barplot(x=data.index, y=data)plt.title("The Expected Income in 3 Months for Listings based on rating")plt.xlabel("Rating")plt.ylabel("average income (next 3 months)")plt.show()
Frome the above figure, it looks like listings with Great location review score are expected to have the highest minimum income for the next three months.
Code
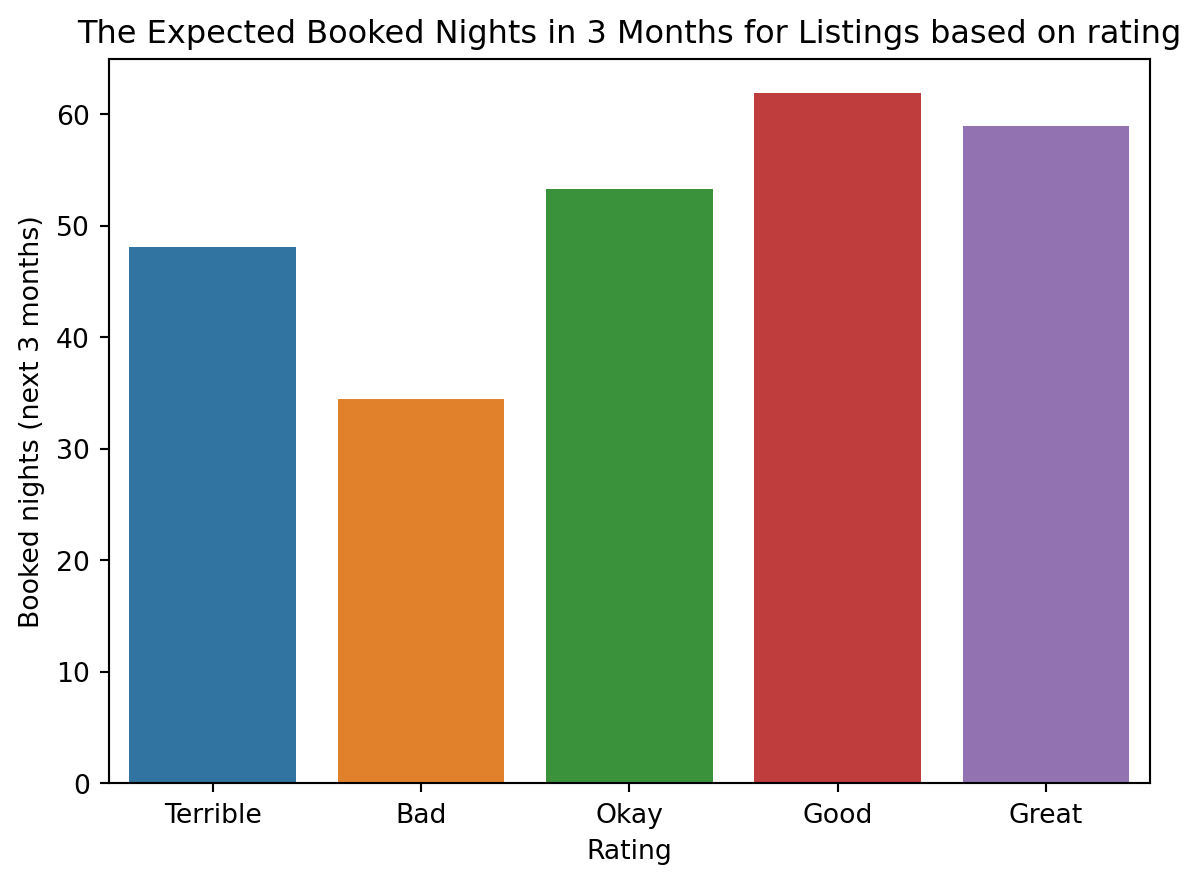
data = romeListings.groupby("rating_location_category")["expected_booked_nights_coming_3m"].mean().sort_values(ascending=False)sns.barplot(x=data.index, y=data)plt.title("The Expected Booked Nights in 3 Months for Listings based on rating")plt.xlabel("Rating")plt.ylabel("Booked nights (next 3 months)")plt.show()
It seems that listings with Great, Good or Okay location review score are expected to be booked more than the other categories for the next three months.
What (Bedrooms, Room Type) combination have highest expected income average for the next 3 months?
Code
nBookedNightinNigh=romeListings.groupby(["room_type","bedrooms"])["expected_income_coming_3m"].agg(["mean","count"])temp=nBookedNightinNigh[nBookedNightinNigh["count"]>11]["mean"].sort_values(ascending=False).head(5)fig = px.bar(x =list(map(str,list(temp.keys()))), y = temp.values, title ="The highest Expected Income average of listings for every (Bedrooms, Room Type) combination", labels={"y": "average income (next 3 months)","x": "(Bedrooms, Room Type)"})fig.show()
Listings that are an entire home or an apartment seems to be expected to have the highest income average for the next three months, and an entire home or an apartment with seven bedrooms are expected to have the highest income average with 65.5K
What (Bedrooms, Room Type) combination have highest minimum income average for the past 12 months?
Code
nBookedNightinNigh=romeListings.groupby(["room_type","bedrooms"])["min_income_past_12m"].agg(["mean","count"])temp=nBookedNightinNigh[nBookedNightinNigh["count"]>11]["mean"].sort_values(ascending=False).head(5)fig = px.bar(x =list(map(str,list(temp.keys()))), y = temp.values, title ="The highest income average of listings for every (Room Type, Number of Bedrooms) combination", labels={"y": "average minimum income of listings (past 12 months)","x": "(Room Type, Number of Bedrooms)"})fig.show()
From the above figure, it seems for the past year, listings that are an entire home or an apartment also have the highest income average for the past year, and an entire home or an apartment with seven bedrooms have the highest income average with 7.8K.
Code
data = romeListings.groupby("bedrooms")["expected_income_coming_3m"].agg(["mean", "count"])data = data[data["count"]>11]["mean"].sort_values(ascending=False).head(10)fig = px.bar(x = data.index, y = data, title ="The highest Expected Income average of listings for every Bedrooms count", labels={"y": "average income (next 3 months)","x": "Number of Bedrooms"})fig.show()
We can see that listings with seven bedrooms are expected to have the highest average income for the next three months, followed by 8, 6 and 5 bedrooms.
Conclusion
To increase the profitabilty of your invesment in Rome:
Have a verification mark.
Have a profile picture.
Invest in the top neighbourhood: ‘II Centro Storico’.
Invest in the room type: Entire Home/Apt in ‘II Centro Storico’, with 7 bedrooms
Try not to exceed the average prices, might lead to bad Scores Value.
Try to response as quick as possible.
Provide an instant booking.
Include the following amenities: WiFi, Hair Dryer, …
Challenges
In this project we faced some challenges, here is some of them:
Choosing a dataset based on cities.
A dataset with more than 70 columns, is not easy.
Cleaning the amenities column, into discrete values.